publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
- ECML’25Pareto Multi-Objective Alignment for Language ModelsQiang He , and Setareh MaghsudiEuropean Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, 2025
LLMs are increasingly deployed in real-world applications requiring careful balancing of multiple, often conflicting, objectives—such as informativeness versus conciseness, or helpfulness versus creativity. However, current alignment methods, primarily based on RLHF, optimize LLMs toward a single reward function, resulting in rigid behavior that fails to capture the complexity and diversity of human preferences. This limitation hinders the adaptability of LLMs to practical scenarios, making multi-objective alignment (MOA) a critical yet underexplored area. To bridge this gap, we propose PAreto Multi-Objective Alignment (PAMA), a principled and computationally efficient algorithm designed explicitly for MOA in LLMs. In contrast to computationally prohibitive gradient-based multi-objective optimization (MOO) methods, PAMA transforms multi-objective RLHF into a convex problem with a closed-form solution, significantly enhancing scalability. Gradient-based MOO approaches suffer from prohibitive O(dn^2) complexity, where d represents the number of model parameters—typically in the billions for LLMs—rendering direct optimization infeasible. PAMA reduces this complexity to O(n) where n is the number of objectives, enabling optimization to be completed within milliseconds. We provide theoretical guarantees showing that PAMA converges to a Pareto stationary point, ensuring that improvements in one objective cannot be achieved without sacrificing others. Extensive experiments across language models ranging from 125M to 7B parameters demonstrate PAMA’s robust and effective multi-objective alignment capabilities, consistently outperforming baseline methods, aligning with its theoretical advantages. By transforming a previously intractable optimization problem into a computationally efficient framework, PAMA offers a practical and theoretically grounded approach to aligning LLMs with diverse human values, paving the way for versatile and adaptable real-world AI deployments.
@article{ecml25, author = {He, Qiang and Maghsudi, Setareh}, title = {Pareto Multi-Objective Alignment for Language Models}, journal = {European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases}, year = {2025} }
2024
- ICML’24Advancing DRL Agents in Commercial Fighting Games: Training, Integration, and Agent-Human AlignmentChen Zhang , Qiang He , Yuan Zhou , and 4 more authorsIn Forty-first International Conference on Machine Learning , 2024
Deep Reinforcement Learning (DRL) agents have demonstrated impressive success in a wide range of game genres. However, existing research primarily focuses on optimizing DRL competence rather than addressing the challenge of prolonged player interaction. In this paper, we propose a practical DRL agent system for fighting games named Shūkai, which has been successfully deployed to Naruto Mobile, a popular fighting game with over 100 million registered users. Shūkai quantifies the state to enhance generalizability, introducing Heterogeneous League Training (HELT) to achieve balanced competence, generalizability, and training efficiency. Furthermore, Shūkai implements specific rewards to align the agent’s behavior with human expectations. Shūkai’s ability to generalize is demonstrated by its consistent competence across all characters, even though it was trained on only 15% of them. Additionally, HELT exhibits a remarkable improvement in sample efficiency. Shūkai serves as a valuable training partner for players in Naruto Mobile, enabling them to enhance their abilities and skills.
-
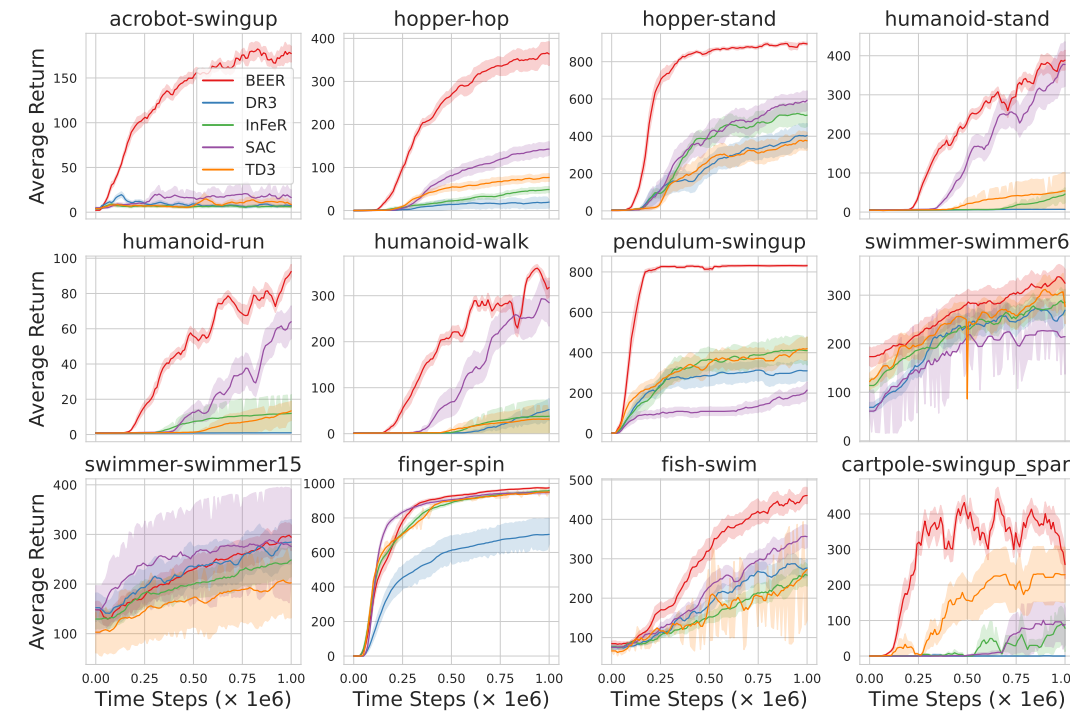 Adaptive Regularization of Representation Rank as an Implicit Constraint of Bellman EquationQiang He , Tianyi Zhou , Meng Fang , and 1 more authorTwelfth International Conference on Learning Representations, 2024
Adaptive Regularization of Representation Rank as an Implicit Constraint of Bellman EquationQiang He , Tianyi Zhou , Meng Fang , and 1 more authorTwelfth International Conference on Learning Representations, 2024Representation rank is an important concept for understanding the role of Neural Networks (NNs) in Deep Reinforcement learning (DRL), which measures the expressive capacity of value networks. Existing studies focus on unboundedly maximizing this rank; nevertheless, that approach would introduce overly complex models in the learning, thus undermining performance. Hence, fine-tuning representation rank presents a challenging and crucial optimization problem. To address this issue, we find a guiding principle for adaptive control of the representation rank. We employ the Bellman equation as a theoretical foundation and derive an upper bound on the cosine similarity of consecutive state-action pairs representations of value networks. We then leverage this upper bound to propose a novel regularizer, namely BEllman Equation-based automatic rank Regularizer (BEER). This regularizer adaptively regularizes the representation rank, thus improving the DRL agent’s performance. We first validate the effectiveness of automatic control of rank on illustrative experiments. Then, we scale up BEER to complex continuous control tasks by combining it with the deterministic policy gradient method. Among 12 challenging DeepMind control tasks, BEER outperforms the baselines by a large margin. Besides, BEER demonstrates significant advantages in Q-value approximation. Our anonymous code is available at https://anonymous.4open.science/r/BEER-3C4B.
@article{ICLR2024-BEER, author = {He, Qiang and Zhou, Tianyi and Fang, Meng and Maghsudi, Setareh}, title = {Adaptive Regularization of Representation Rank as an Implicit Constraint of Bellman Equation}, journal = {Twelfth International Conference on Learning Representations}, year = {2024}, } -
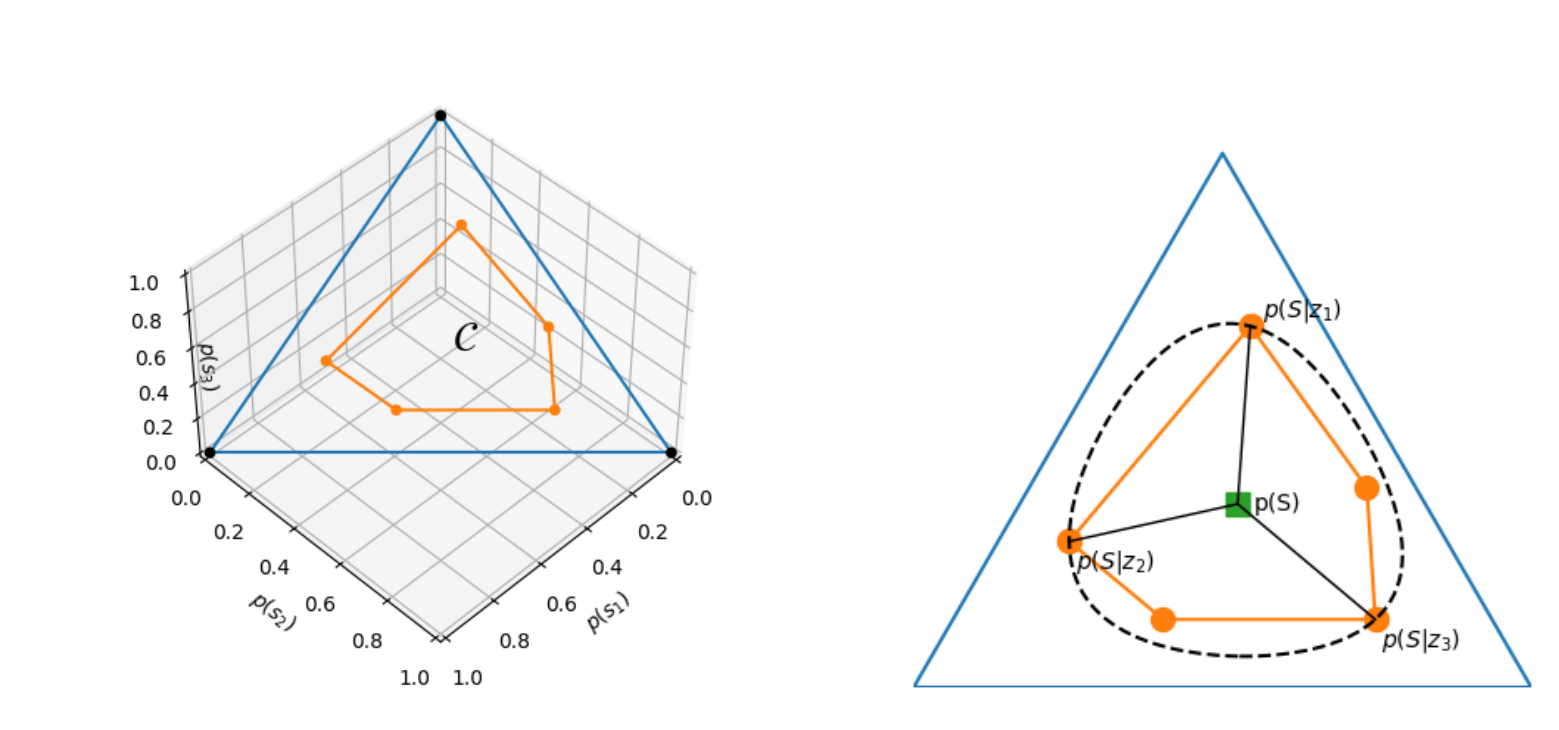 Task Adaptation from Skills: Information Geometry, Disentanglement, and New Objectives for Unsupervised Reinforcement LearningYucheng Yang , Tianyi Zhou , Qiang He , and 3 more authorsSpotlight, Twelfth International Conference on Learning Representations, 2024
Task Adaptation from Skills: Information Geometry, Disentanglement, and New Objectives for Unsupervised Reinforcement LearningYucheng Yang , Tianyi Zhou , Qiang He , and 3 more authorsSpotlight, Twelfth International Conference on Learning Representations, 2024Spotlight
Unsupervised reinforcement learning (URL) aims to learn general skills for unseen downstream tasks. Mutual Information Skill Learning (MISL) addresses URL by maximizing the mutual information between states and skills but lacks sufficient theoretical analysis, e.g., how well its learned skills can initialize a downstream task’s policy. Our new theoretical analysis shows that the diversity and separatability of learned skills are fundamentally critical to downstream task adaptation but MISL does not necessarily guarantee them. To improve MISL, we propose a novel disentanglement metric LSEPIN and build an information-geometric connection between LSEPIN and downstream task adaptation cost. For better geometric properties, we investigate a new strategy that replaces the KL divergence in information geometry with Wasserstein distance. We extend the geometric analysis to it, which leads to a novel skill-learning objective WSEP. It is theoretically justified to be helpful to task adaptation and it is capable of discovering more initial policies for downstream tasks than MISL. We further propose a Wasserstein distance-based algorithm PWSEP can theoretically discover all potentially optimal initial policies.
@article{ICLR2024-spotlight, author = {Yang, Yucheng and Zhou, Tianyi and He, Qiang and Han, Lei and Pechenizkiy, Mykola and Fang, Meng}, title = {Task Adaptation from Skills: Information Geometry, Disentanglement, and New Objectives for Unsupervised Reinforcement Learning}, journal = {Spotlight, Twelfth International Conference on Learning Representations}, year = {2024}, highlight = {Spotlight}, }


2023
-
 Keep Various Trajectories: Promoting Exploration of Ensemble Policies in Continuous ControlChao Li , Chen Gong , Qiang He , and 1 more authorThirty-seventh Conference on Neural Information Processing Systems, 2023
Keep Various Trajectories: Promoting Exploration of Ensemble Policies in Continuous ControlChao Li , Chen Gong , Qiang He , and 1 more authorThirty-seventh Conference on Neural Information Processing Systems, 2023The combination of deep reinforcement learning (DRL) with ensemble methods has been proved to be highly effective in addressing complex sequential decision-making problems. This success can be primarily attributed to the utilization of multiple models, which enhances both the robustness of the policy and the accuracy of value function estimation. However, there has been limited analysis of the empirical success of current ensemble RL methods thus far. Our new analysis reveals that the sample efficiency of previous ensemble DRL algorithms may be limited by sub-policies that are not as diverse as they could be. Motivated by these findings, our study introduces a new ensemble RL algorithm, termed \textbfTrajectories-awar\textbfE \textbfEnsemble exploratio\textbfN (TEEN). The primary goal of TEEN is to maximize the expected return while promoting more diverse trajectories. Through extensive experiments, we demonstrate that TEEN not only enhances the sample diversity of the ensemble policy compared to using sub-policies alone but also improves the performance over ensemble RL algorithms. On average, TEEN outperforms the baseline ensemble DRL algorithms by 41% in performance on the tested representative environments.
@article{NIPS23, author = {Li, Chao and Gong, Chen and He, Qiang and Hou, Xinwen}, title = {Keep Various Trajectories: Promoting Exploration of Ensemble Policies in Continuous Control}, journal = {Thirty-seventh Conference on Neural Information Processing Systems}, year = {2023}, } - ECML’23Eigensubspace of Temporal-Difference Dynamics and How It Improves Value Approximation in Reinforcement LearningQiang He , Meng Fang , Tianyi Zhou , and 1 more authorEuropean Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, 2023
We propose a novel value approximation method, namely Eigensubspace Regularized Critic (ERC) for deep reinforcement learning (RL). ERC is motivated by an analysis of the dynamics of Q-value approximation error in the Temporal-Difference (TD) method, which follows a path defined by the 1-eigensubspace of the transition kernel associated with the Markov Decision Process (MDP). It reveals a fundamental property of TD learning that has remained unused in previous deep RL approaches. In ERC, we propose a regularizer that guides the approximation error tending towards the 1-eigensubspace, resulting in a more efficient and stable path of value approximation. Moreover, we theoretically prove the convergence of the ERC method. Besides, theoretical analysis and experiments demonstrate that ERC effectively reduces the variance of value functions. Among 26 tasks in the DMControl benchmark, ERC outperforms state-of-the-art methods for 20. Besides, it shows significant advantages in Q-value approximation and variance reduction. Our code is available at this https URL.
@article{ecml23, author = {He, Qiang and Fang, Meng and Zhou, Tianyi and Maghsudi, Setareh}, title = {Eigensubspace of Temporal-Difference Dynamics and How It Improves Value Approximation in Reinforcement Learning}, journal = {European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases}, volume = {abs/2205.14557}, year = {2023}, url = {https://arxiv.org/abs/2306.16750}, doi = {10.48550/arXiv.2205.14557}, eprinttype = {arXiv}, eprint = {2205.14557}, } - CVPR’23Frustratingly Easy Regularization on Representation Can Boost Deep Reinforcement LearningQiang He , Huangyuan Su , Jieyu Zhang , and 1 more authorThe Thirty-Fourth IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
Deep reinforcement learning (DRL) gives the promise that an agent learns good policy from high-dimensional information, whereas representation learning removes irrelevant and redundant information and retains pertinent information. In this work, we demonstrate that the learned representation of the Q-network and its target Q-network should, in theory, satisfy a favorable distinguishable representation property. Specifically, there exists an upper bound on the representation similarity of the value functions of two adjacent time steps in a typical DRL setting. However, through illustrative experiments, we show that the learned DRL agent may violate this property and lead to a sub-optimal policy. Therefore, we propose a simple yet effective regularizer called Policy Evaluation with Easy Regularization on Representation (PEER), which aims to maintain the distinguishable representation property via explicit regularization on internal representations. And we provide the convergence rate guarantee of PEER. Implementing PEER requires only one line of code. Our experiments demonstrate that incorporating PEER into DRL can significantly improve performance and sample efficiency. Comprehensive experiments show that PEER achieves state-of-the-art performance on all 4 environments on PyBullet, 9 out of 12 tasks on DMControl, and 19 out of 26 games on Atari. To the best of our knowledge, PEER is the first work to study the inherent representation property of Q-network and its target. Our code is available at this https URL.
@article{cvpr2023, author = {He, Qiang and Su, Huangyuan and Zhang, Jieyu and Hou, Xinwen}, title = {Frustratingly Easy Regularization on Representation Can Boost Deep Reinforcement Learning}, journal = {The Thirty-Fourth IEEE/CVF Conference on Computer Vision and Pattern Recognition}, volume = {abs/2205.14557}, year = {2023}, url = {https://openaccess.thecvf.com/content/CVPR2023/papers/He_Frustratingly_Easy_Regularization_on_Representation_Can_Boost_Deep_Reinforcement_Learning_CVPR_2023_paper.pdf}, doi = {10.48550/arXiv.2205.14557}, eprinttype = {arXiv}, eprint = {2205.14557}, } - AAMAS’23Centralized Cooperative Exploration Policy for Continuous Control TasksChao Li , Chen Gong , Qiang He , and 2 more authorsIn The 22nd International Conference on Autonomous Agents and Multiagent Systems , 2023
The deep reinforcement learning (DRL) algorithm works brilliantly on solving various complex control tasks. This phenomenal success can be partly attributed to DRL encouraging intelligent agents to sufficiently explore the environment and collect diverse experiences during the agent training process. Therefore, exploration plays a significant role in accessing an optimal policy for DRL. Despite recent works making great progress in continuous control tasks, exploration in these tasks has remained insufficiently investigated. To explicitly encourage exploration in continuous control tasks, we propose CCEP (Centralized Cooperative Exploration Policy), which utilizes underestimation and overestimation of value functions to maintain the capacity of exploration. CCEP first keeps two value functions initialized with different parameters, and generates diverse policies with multiple exploration styles from a pair of value functions. In addition, a centralized policy framework ensures that CCEP achieves message delivery between multiple policies, furthermore contributing to exploring the environment cooperatively. Extensive experimental results demonstrate that CCEP achieves higher exploration capacity. Empirical analysis shows diverse exploration styles in the learned policies by CCEP, reaping benefits in more exploration regions. And this exploration capacity of CCEP ensures it outperforms the current state-of-the-art methods across multiple continuous control tasks shown in experiments.
@inproceedings{ccep, author = {Li, Chao and Gong, Chen and and Qiang He and Hou, Xinwen and Liu, Yu}, title = {Centralized Cooperative Exploration Policy for Continuous Control Tasks}, booktitle = {The 22nd International Conference on Autonomous Agents and Multiagent Systems}, pages = {4008--4012}, publisher = {{ACM}}, year = {2023}, }

2022
- ICASSP‘22POPO: Pessimistic Offline Policy OptimizationQiang He , Xinwen Hou , and Yu LiuIn IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2022, Virtual and Singapore, 23-27 May 2022 , 2022
Offline reinforcement learning (RL) aims to optimize policy from large pre-recorded datasets without interaction with the environment. This setting offers the promise of utilizing diverse and static datasets to obtain policies without costly, risky, active exploration. However, commonly used off-policy deep RL methods perform poorly when facing arbitrary off-policy datasets. In this work, we show that there exists an estimation gap of value-based deep RL algorithms in the offline setting. To eliminate the estimation gap, we propose a novel offline RL algorithm that we term Pessimistic Offline Policy Optimization (POPO), which learns a pessimistic value function. To demonstrate the effectiveness of POPO, we perform experiments on various quality datasets. And we find that POPO performs surprisingly well and scales to tasks with high-dimensional state and action space, comparing or outperforming tested state-of-the-art offline RL algorithms on benchmark tasks.
@inproceedings{DBLP:conf/icassp/HeHL22, author = {He, Qiang and Hou, Xinwen and Liu, Yu}, title = {{POPO:} Pessimistic Offline Policy Optimization}, booktitle = {{IEEE} International Conference on Acoustics, Speech and Signal Processing, {ICASSP} 2022, Virtual and Singapore, 23-27 May 2022}, pages = {4008--4012}, publisher = {{IEEE}}, year = {2022}, url = {https://doi.org/10.1109/ICASSP43922.2022.9747886}, doi = {10.1109/ICASSP43922.2022.9747886}, timestamp = {Tue, 07 Jun 2022 17:34:54 +0200}, biburl = {https://dblp.org/rec/conf/icassp/HeHL22.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, }
2021
- ICME’21Wide-Sense Stationary Policy Optimization with Bellman Residual on Video GamesChen Gong* , Qiang He* , Yunpeng Bai , and 3 more authorsIn 2021 IEEE International Conference on Multimedia and Expo, ICME 2021, Shenzhen, China, July 5-9, 2021 , 2021
Deep Reinforcement Learning (DRL) has an increasing application in video games. However, it usually suffers from unstable training, low sampling efficiency, etc. Under the assumption that Bellman residual follows a stationary random process when the training process is convergent, we propose the Wide-sense Stationary Policy Optimization (WSPO) framework, which leverages the Wasserstein distance from the Bellman Residual Distribution (BRD) between two adjacent time steps, to stabilize the training stage and improve the sampling efficiency. We minimize the Wasserstein distance with Quantile Regression, where the specific form of BRD is not needed. Finally, we combine WSPO with Advantage Actor-Critic (A2C) algorithm and Deep Deterministic Policy Gradient (DDPG) algorithm. We evaluate WSPO on Atari 2600 video games and continuous control tasks, illustrating that WSPO compares or outperforms the state-of-the-art algorithms we tested.
@inproceedings{DBLP:conf/icmcs/GongHBHFL21, author = {Gong*, Chen and He*, Qiang and Bai, Yunpeng and Hou, Xinwen and Fan, Guoliang and Liu, Yu}, title = {Wide-Sense Stationary Policy Optimization with Bellman Residual on Video Games}, booktitle = {2021 {IEEE} International Conference on Multimedia and Expo, {ICME} 2021, Shenzhen, China, July 5-9, 2021}, pages = {1--6}, publisher = {{IEEE}}, year = {2021}, url = {https://doi.org/10.1109/ICME51207.2021.9428293}, doi = {10.1109/ICME51207.2021.9428293}, timestamp = {Thu, 03 Feb 2022 12:45:49 +0100}, biburl = {https://dblp.org/rec/conf/icmcs/GongHBHFL21.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, }
2020
- ICTAI’20WD3: Taming the Estimation Bias in Deep Reinforcement LearningQiang He , and Xinwen HouIn 32nd IEEE International Conference on Tools with Artificial Intelligence, ICTAI 2020, Baltimore, MD, USA, November 9-11, 2020 , 2020
The overestimation phenomenon caused by function approximation is a well-known issue in value-based reinforcement learning algorithms such as deep Q-networks and DDPG, which could lead to suboptimal policies. To address this issue, TD3 takes the minimum value between a pair of critics. In this paper, we show that the TD3 algorithm introduces underestimation bias in mild assumptions. To obtain a more precise estimation for value function, we unify these two opposites and propose a novel algorithm \underlineWeighted \underlineDelayed \underlineDeep \underlineDeterministic Policy Gradient (WD3), which can eliminate the estimation bias and further improve the performance by weighting a pair of critics. To demonstrate the effectiveness of WD3, we compare the learning process of value function between DDPG, TD3, and WD3. The results verify that our algorithm does eliminate the estimation error of value functions. Furthermore, we evaluate our algorithm on the continuous control tasks. We observe that in each test task, the performance of WD3 consistently outperforms, or at the very least matches, that of the state-of-the-art algorithms. Our code is available at https://sites.google.com/view/ictai20-wd3/.
@inproceedings{DBLP:conf/ictai/HeH20, author = {He, Qiang and Hou, Xinwen}, title = {{WD3:} Taming the Estimation Bias in Deep Reinforcement Learning}, booktitle = {32nd {IEEE} International Conference on Tools with Artificial Intelligence, {ICTAI} 2020, Baltimore, MD, USA, November 9-11, 2020}, pages = {391--398}, publisher = {{IEEE}}, year = {2020}, url = {https://doi.org/10.1109/ICTAI50040.2020.00068}, doi = {10.1109/ICTAI50040.2020.00068}, timestamp = {Mon, 04 Jan 2021 18:04:30 +0100}, biburl = {https://dblp.org/rec/conf/ictai/HeH20.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, }